说明:本文是笔者之前给公司公众号写的两篇隐形水印科普文章的整合与扩充,介绍了能够在视频数据中嵌入隐形数据的技术。
前言
起初笔者只是被论坛里一个讨论隐写术的帖子引起了兴趣,期望找到一种隐藏的信息经过转码甚至屏摄后依然不会丢失的视频隐写技术,即一种可靠的隐形数字水印技术。遗憾的是一番资料查下来,发现现有的技术和笔者的期望依然存在一定距离。但查都查了,这里还是分类总结一下。
封装级水印
首先是实现最简单的封装级水印。视频封装即视频容器层的数据,通俗地理解就是文件格式。这里贴张图科普一下视频文件的基本构成。
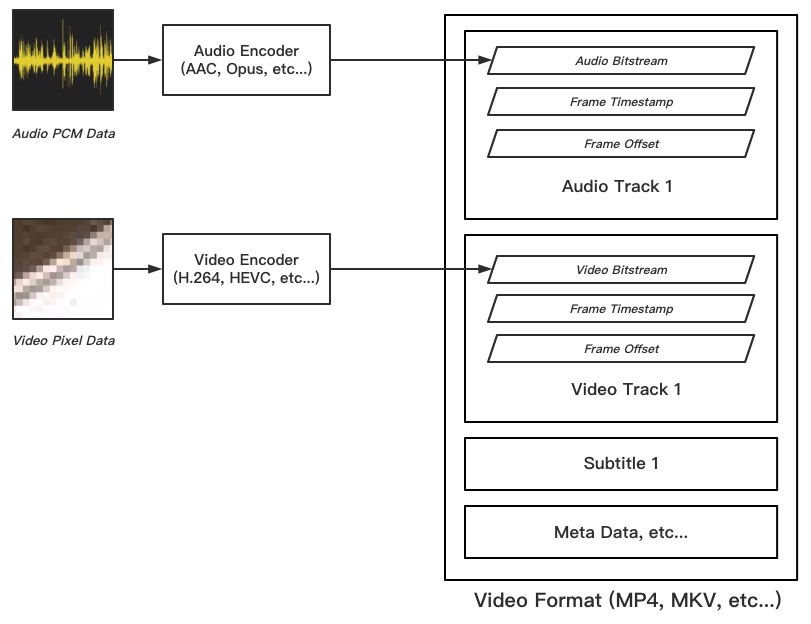 视频文件的基本结构
视频文件的基本结构
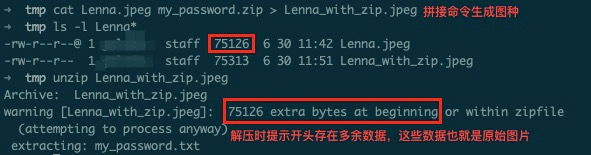
因为这一层数据是和外界直接交互的,所以只要熟悉格式标准就能通过改写二进制数据来嵌入数据。曾经流行的图种就是一种最简单的图像封装层的隐写。也许有些人不知道图种是什么。简单地说,如果你从网络上下载了一张jpeg图片,用解压软件对它进行解压,能得到其他文件,比如某某种子,那么这种隐藏了数据的图片就叫图种。它过去在网络论坛上被广泛使用,人们用它来传播各种无版权资源。制作图种很简单,只需要一条命令,把jpeg文件和zip文件进行二进制拼接即可。
1
cat a.jpg b.zip > output.jpg
 图种的生成与解压
图种的生成与解压
 图种可以被正常显示
图种可以被正常显示
为什么这种文件能正常工作呢。因为jpeg格式的文件,是以一串固定数据(0xFFD9)结尾的[1];而zip格式的文件,也有其固定的起始码(0x04034B50)[2]。现在大部分图片浏览器和解压软件都有对数据首尾位置不正常的情况做兼容,所以它们会直接忽略首尾标记范围以外的数据。
那么,图种毕竟只是图片,如果是格式更复杂的视频,是否也存在利用封装结构来隐藏数据的方法呢?那可太多了。事实上,大部分视频格式都有存储附属信息的结构,播放器在解析文件时基本都会忽略这些信息,因为它们不知道怎么处理这些东西。所以我们只要把数据藏在那里就行了。下面简单举几个例子。
flv文件
flv文件由一个header和大量的tag组成,这些tag分为三类:audio、video和script data。其中script data的格式标准支持插入各类自定义数据[3]。我们可以对照官方文档来实现代码修改这个tag的数据。嫌麻烦的话,一些开源软件也支持在一定程度上的修改它,比如flvmeta,虽然这个工具只支持插入字符串:
1
flvmeta -U -a keyString:valueString movie.flv
 使用flvmeta修改flv文件,加入自定义数据
使用flvmeta修改flv文件,加入自定义数据
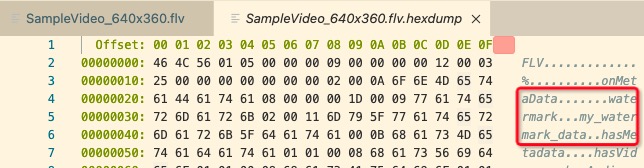 实际存储在文件中的数据
实际存储在文件中的数据
mp4文件
mp4文件由大量的,可嵌套的box组成。因为box的类型非常多,大部分播放器只会选择它需要的box去解析。因此我们可以自定义一些box类型去嵌入数据。但是由于mp4比flv格式复杂不少,还是推荐直接使用辅助工具。这里用比较常见的mp4box来举个例子:
1
2
3
4
5
6
7
8
# 在mp4中新建一个自定义box
MP4Box -set-meta aaaa sample.mp4
# 在刚才新建的box中嵌入数据,id自己定,需要记住
MP4Box -add-item wow.jpg:id=111:name=hiddenData:type=bbbb sample.mp4
# 导出嵌入的数据,111就是上面嵌入的id
MP4Box -dump-item 111:path=dump.jpg sample.mp4
顺便一提,笔者使用的1.0.1版本的mp4box,导出meta会有IO错误。起初笔者一直以为是自己使用方式有问题,但下载代码debug后发现其实是mp4box自己的bug。它先close了文件再flush!查了一下master分支这个问题已经修复了,估计下个版本就好了。读者使用这个工具时请注意版本号。
H.264码流
在flv、mp4、mkv等文件格式上添加数据,意味着视频必须以离线文件的形式存在。如果我们希望在直播或者视频通话中的视频数据上添加水印呢?这时我们可以在更下一层,也就是视频码流层下手。码流即本文第一张图《视频文件的基本结构》中的bitstream,它是编码压缩后的数据,可以被存储在各种封装格式中。
视频编码有很多标准,现在使用最广泛的H.264标准中,有一段数据叫做SEI(补充增强信息,Supplemental Enhancement Information),它被用来存储辅助解码与显示的信息,支持添加用户的自定义数据。著名的开源编码器x264就在这段数据里写了自己的版本信息以及编码参数。我们可以参照格式标准生成自己定义的SEI数据,再嵌入视频码流中,从而实现隐形水印。
 自定义SEI的语法标准[4]
自定义SEI的语法标准[4]
 x264生成的SEI数据
x264生成的SEI数据
封装结构层的水印是所有隐形水印中运算量最小的,因为它不涉及到视频的编解码。但是其缺点也很明显。视频在被传播的过程中极可能被人重新编码存储,在这个过程中,事先添加在这一层的自定义数据一般都会丢失。因此这类方法仅在一些特殊的场景被使用。
空间域(像素域)水印
对于大部分人来说,比起封装格式,可能对像素数据更熟悉一些。我们知道一张数字图像一般是由若干个通道的二维数据,也就是很多像素点构成的。单个通道的像素点数据一般是8比特位(HDR会多一点),当其最低位被修改时,一般很难被人眼观察到,所以我们可以把隐藏数据写在这里。这种方法我们称为LSB(Least Significant Bit)方法。下图的十个方块,蓝色通道的像素值依次由246递增至255,相邻的两个方块相当于修改了LSB数据。
 修改LSB数据较难被肉眼分辨
修改LSB数据较难被肉眼分辨
至于具体实现,这里介绍最粗暴的一种。先把水印数据转化成只有0和1的二值图像,然后直接写到目标图像的最低位上,这样就完成了水印的嵌入。下面我们用python简单实现一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import cv2
# 读取图像,将水印缩放至目标图像大小,并二值化
ori_img = cv2.imread('Lenna.jpg')
watermark = cv2.imread('watermark.jpg')
## 既然是二值图像,使用最近邻方式来拉伸比较合适,可以防止插值造成边缘模糊
resized_watermark = cv2.resize(watermark, ori_img.shape[:2], interpolation=cv2.INTER_NEAREST)
binary_watermark = resized_watermark >> 7
# 嵌入水印并保存结果
output_img = ori_img & 0xFE | binary_watermark
cv2.imwrite('Lenna_with_watermark.png', output_img)
# 提取水印
img_with_watermark = cv2.imread('Lenna_with_watermark.png')
extracted_watermark = ((target_img & 0x01) * 255)
cv2.imwrite('extracted_watermark.jpg', extracted_watermark)
 原始图片
原始图片
 待添加水印
待添加水印
 添加完水印的图片
添加完水印的图片
 提取出的水印
提取出的水印
细心的读者会发现,代码中其他图像都是使用jpg格式存储的,唯独添加完水印的图片代码中使用了png格式。这是因为最低有效位的数据非常脆弱,极容易被有损压缩算法破坏,导致水印无法正常提取。而png格式是无损压缩格式,不会引入这个干扰。如果把上述代码中的png换成jpg,你会看到提取出的水印变得完全无法辨认。即便我们以增加视觉损失为代价把写入的比特从最低位提高一些,依然不能保证水印的完整性。
 图片经过有损压缩后提取的水印
图片经过有损压缩后提取的水印
LSB类型的隐形水印,或者说隐写术,因为其原理通俗易懂,所以使用比较广泛。它经常出现在一些线上解谜中,也有一些现成的工具帮助分析,比如stegsolve。另外,一些公司会用它在内部文档上做水印,用来在泄漏时追究员工责任。
变换域水印
LSB方法依然存在添加的水印经过有损压缩后容易丢失的问题。为了提高水印的鲁棒性,一些人提出了在变换域上添加水印的方法。所谓变换域,是相对前一节的空间域(像素域)而言的。一般我们管原始的像素数据叫空间域(Spatial Domain)系数,因为每一个像素都代表它所在坐标的空间位置的采样值。当我们希望从另一个角度分析图像,就会对图像进行线性变换,也就有了各种变换域。最常用的变换域就是频率域,它有很多优秀的性质方便我们分析和操作数据。
 频域变换示意图[5]
频域变换示意图[5]
基于DCT的方法
DCT即离散余弦变换,它的2D形式可以把空间域图像转换到频率域,在图像处理领域被广泛应用。关于它的细节,可以阅读此链接:详解离散余弦变换(DCT)。不过其实只要了解个大概,也能读懂本节内容。基于DCT的隐形水印是一类很常见的隐形水印算法。选择DCT的原因有很多。
- 一是人眼对图像中不同频率的信号敏感程度不同,直接在频率域上操作数据有利于控制主观感知到的失真程度,以保证水印的
隐形。 - 二是不同频率的信号稳定性不同,在频率域加水印有助于控制水印的
鲁棒性,保证水印在载体经历各类损伤后依然能够还原出来。 - 三是理论上这类方法可以直接嵌入一些编码器,从而减少运算量。比如jpeg压缩过程中就使用了DCT。
但需要注意的是,上述一二两点其实是有矛盾的,水印数据所属的频率范围越低,鲁棒性越高,但图像的视觉损失也越大,反之亦然。因此大部分实现会选择在中频范围内添加水印。
下图是一个常见的水印嵌入流程。图像经过DCT变换后,把水印数据加到选好的频率系数上,再使用IDCT还原图像,这样水印的嵌入就完成了。
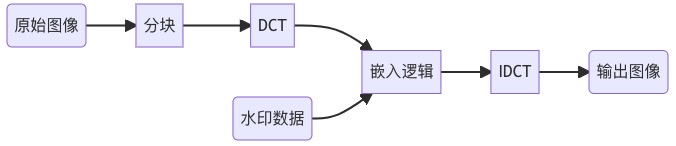 DCT嵌入水印流程
DCT嵌入水印流程
如果在提取水印时有原始图像作为参考,则图中的嵌入逻辑一般有如下几种选择。式中vi表示原始系数,xi表示水印系数,α为常量。
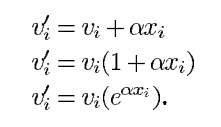 有参时的水印嵌入公式[6]
有参时的水印嵌入公式[6]
其对应的水印提取流程如下:
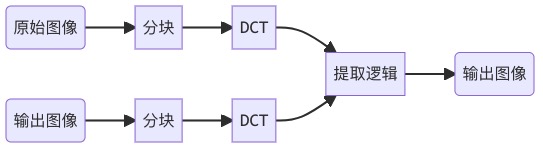 DCT有参提取水印流程
DCT有参提取水印流程
如果没有原始图像做参考,那么可以参考上篇的LSB方法,在嵌入时将原始系数以低精度形式量化,再将水印数据存储在高精度的区域中。
基于DWT与SVD的方法
上文有提到隐形水印算法需要同时满足低视觉损失和高鲁棒性。能达到这个效果的工具不止DCT,DWT和SVD也是两个常见的选择。其中DWT一般使用Haar小波,其运算量较低,可以将图像分解成不同频带的四份,并且可以递归地执行多次,显著减少后续需要处理的数据量。因此它常被用来做隐形水印的预处理。而SVD则是将图像数据单纯地视为二维矩阵,利用奇异值的稳定性来保护水印。
下图是一个结合DWT和SVD的隐形水印例子。图中虽然仅进行了一轮DWT,并选择了LL低频数据进行处理。但实际上也存在使用多轮DWT,以及利用LH和HL数据做SVD的实现。它们对应的水印提取流程也只是个逆过程,这里就不再贴图了。
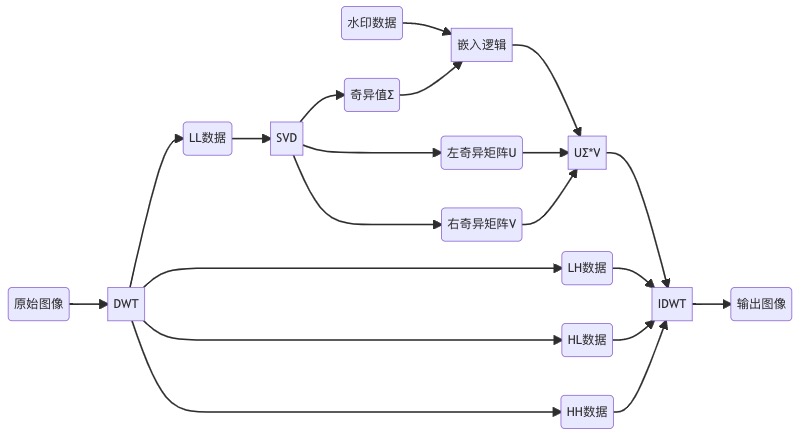 DWT+SVD嵌入水印流程
DWT+SVD嵌入水印流程
关于变换域方法的实现细节,这里推荐阅读python开源库invisible-watermark。它实现了多种算法,复合使用了DCT、DWT、SVD,代码量也很小,比较适合阅读。另外这个库还实现了一种机器学习水印算法。下文会提到。
时间域水印
前文提到的几个方法基本都是把视频看作单帧图像来进行处理。对于相比图像多了一个维度(时间维度)的视频来说,当然存在利用这个维度来嵌入水印的例子。
关于时间维度的粒度,有的算法是以帧(frame)为单位,有的则是以场景(scene)为单位。帧很好理解,每一帧画面嵌入一定的数据,比如水印的某个比特位,最后组合得到结果。而场景则是指视频的镜头内容,当发生镜头切换时,画面内容会发生大幅度变化,算法认为这时该嵌入下一组数据。它的好处是不受帧率限制,转码后发生帧率变化时依然有效;坏处是场景切换检测的准确度有待商榷。比如笔者看到的论文使用了最简单的SAD(Sum of Absolute Differences)作为切换判断,考虑到现代视频的内容复杂,剪辑手法多样,还存在大量短视频,这种方法很容易出现问题。
机器学习水印
当我们发现传统图像处理算法效果提升不上去了的时候,基本都可以去试试机器学习。上文提到的python库invisible-watermark中,就提供了一种被称为RivaGAN可选算法来嵌入和提取水印数据。顾名思义,它是一种基于GAN实现的神经网络。在训练过程中,研究者分别使用了一个Critic网络评估画面失真和一个Adversary网络模拟主动攻击,用它们作为对抗源来训练网络,以期同时在画面质量和鲁棒性方面得到较好的结果。另外还有一个人工设计的Noise网络被用来模拟常见的传输失真(包括缩放,裁剪,有损压缩),用以进一步提升模型鲁棒性。下图是RivaGAN的网络结构,github上有它的完整实现。
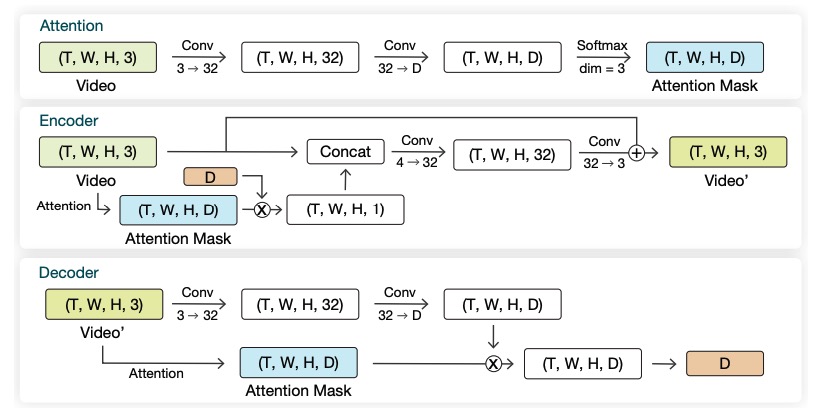 RivaGAN的编解码流程[7]
RivaGAN的编解码流程[7]
其他方案
在搜索过程中,笔者还发现了一些比较少见的方案。比如利用数独的可恢复性,将水印分割成9块,以数独的形式嵌入,从而在画面不完整的情况下通过解数独的方法恢复出水印。摘要里描述这种方法最高可以应对98.8%的画面损失[8]。另外还有一类,是把水印数据嵌入在梯度方向中[9]。这种技术相比其他方法在对抗画面缩放攻击方面有一定优势。
水印的混淆与加密
使用隐形水印时一般需要公开算法,毕竟当要用水印鉴定所属人时,没有人信任一个黑盒子的提取结果。但公开后,再复杂的水印嵌入方法都有被攻击者提取甚至替换可能性。为了防止这种情况,在嵌入水印时,往往会对水印数据本身或者嵌入的坐标信息进行混淆加密,通过key的形式管理。这样一来,只要攻击者没有密钥,即便他们已经知道水印的嵌入方式,也没办法探测出原有的水印数据。
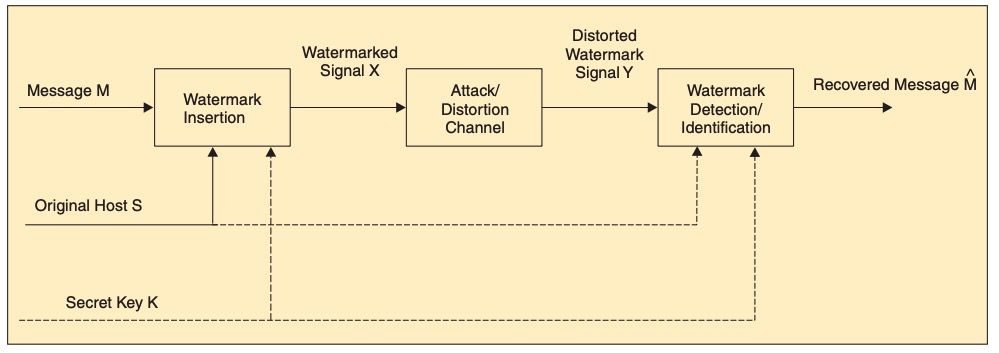 完整的隐形水印系统[10]
完整的隐形水印系统[10]
总结
开头也说了,现有的隐形水印算法基本都不够可靠。如果攻击者知道原理,替换水印也许做不到(有混淆的存在),但抹除它还是没问题的。即便不知道原理,只要攻击者能够接受画质损失,那么单单通过屏摄,就能抹除九成九的水印。因为屏摄引入的图像失真是一种复合类型的失真,空域、频域、梯度方向等等都会受到影响,即便是机器学习算法,也不一定能经受得起屏摄的挑战。所以要在生产环境中应用隐形水印的话,一定要清楚它的局限性,适度使用。
参考文献
[1] CCITT Rec. T.81
[2] APPNOTE.TXT - .ZIP File Format Specification
[3] Adobe Flash Video File Format Specification
[4] Recommendation ITU-T H.264
[5] https://en.wikipedia.org/wiki/Frequency_domain
[6] I.J. Cox, J. Kilian, F.T. Leighton, T. Shamoon. Secure spread spectrum watermarking for multimedia. 1997.
[7] Zhang, Kevin Alex and Xu, Lei and Cuesta-Infante, Alfredo and Veeramachaneni, Kalyan. Robust Invisible Video Watermarking with Attention. MIT EECS, September 2019.
[8] Mohammad Shahab Goli, Alireza Naghsh. Introducing a New Method Robust Against Crop Attack In Digital Image Watermarking Using Two-Step Sudoku. 2017.
[9] Ehsan Nezhadarya, Z. Jane Wang, Rabab Kreidieh Ward. Robust Image Watermarking Based on Multiscale Gradient Direction Quantization. 2011.
[10] C.I. Podilchuk, E.J. Delp. Digital watermarking: algorithms and applications. 2001.